What it does
Core capabilities at a glance
- Workspace-based document isolation
- Native Ollama, LM Studio, vLLM, OpenAI, Anthropic providers
- Built-in vector DB (LanceDB) - no setup
- Multi-user with permissions
- Agent skills (web scrape, search, summarize)
- Embeddable chat widget for your site
- PDF, DOCX, audio, YouTube, GitHub ingest
- Native desktop app + Docker server
Deep dive
The full breakdown - performance, comparisons, and setup
AnythingLLM
Short answer: AnythingLLM is the most complete out-of-the-box local RAG platform. Where Open WebUI is "ChatGPT but self-hosted", AnythingLLM is "ChatGPT-with-your-documents but self-hosted" - workspaces, document isolation, agents, and an embeddable widget all built in.
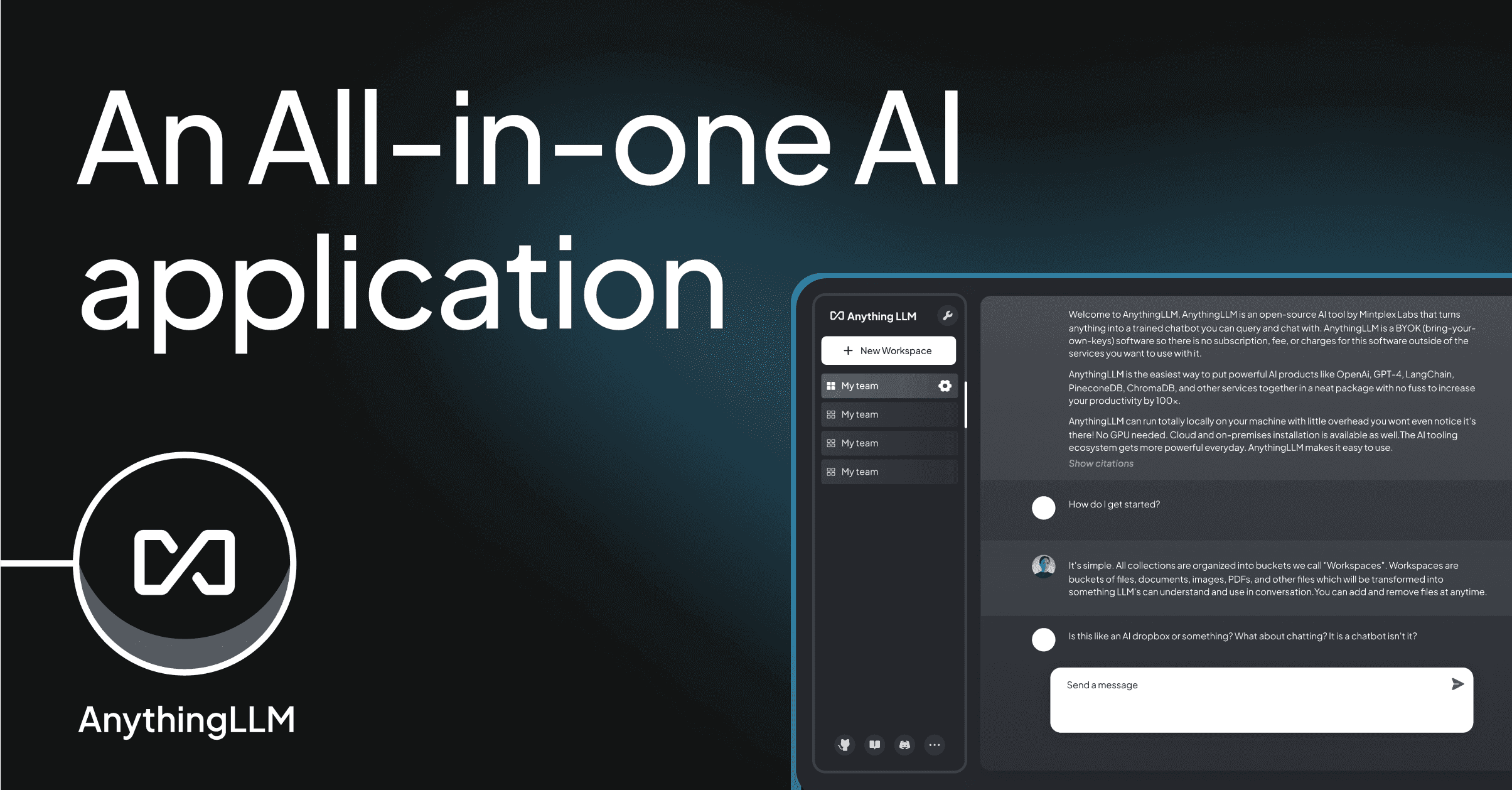
What it is
AnythingLLM is a full-stack RAG application that ships as either a desktop app or a Docker container. It includes its own vector database (LanceDB), its own embedder, and a workspace abstraction that lets you keep different document sets cleanly separated.
You point it at Ollama / LM Studio / vLLM / OpenAI / Anthropic and you have a fully working document-QA system in minutes - no vector DB to provision, no embedding pipeline to write.
Why it's the right pick for RAG
- Zero infra RAG - LanceDB is embedded; no Qdrant/Pinecone to host
- Workspaces - each workspace has its own docs, settings, model, and chat history; perfect for multi-project or multi-tenant
- Ingest everything - PDF, DOCX, audio transcripts, YouTube, GitHub repos, arbitrary URLs
- Embeddable widget - drop a script tag on your site, instant on-prem chatbot
- Agents - workspace-scoped agents with web search, web scrape, summarize, save-memory tools
Real-world setups
| Use case | Hardware | LLM | Embedder |
|---|---|---|---|
| Personal docs (~1k pages) | M4 Mac Mini 16GB | Qwen3 8B via Ollama | built-in (all-MiniLM) |
| Team knowledge base (10k pages) | RTX 4090 | Qwen3 30B via Ollama | nomic-embed-text |
| On-prem doc-chatbot for clients | dual 4090 server | Llama 3.3 70B via vLLM | bge-large-en |
| Embedded site widget | hosted backend | Mistral Small 3 | jina-embeddings-v3 |
How it compares
| AnythingLLM | Open WebUI | LibreChat | Danswer | |
|---|---|---|---|---|
| Built-in vector DB | ✓ (LanceDB) | ✗ (use Chroma/Qdrant) | ✗ | ✓ |
| Workspaces / tenants | ✓✓ | basic | basic | basic |
| Embeddable widget | ✓ | ✗ | ✗ | ✗ |
| Native agents | ✓ | ✓ | ✓ | ✓ |
| Best for | RAG-heavy + multi-tenant | general chat + RAG | OpenAI-style team chat | enterprise search |
Frequently asked
Open WebUI vs AnythingLLM - which one?
Open WebUI if your primary use is chat with optional document upload. AnythingLLM if your primary use is "talk to my documents" or you need workspace isolation. Many teams run both.
Does it work fully offline?
Yes if you use a local LLM + local embedder. No data leaves your network.
Can I use it as a customer support chatbot on my site?
Yes - the embeddable widget is designed exactly for this. Pair with a workspace scoped to your docs.
Get started
Docker:
docker run -d --name anythingllm \
-p 3001:3001 \
-v anythingllm-storage:/app/server/storage \
--cap-add SYS_ADMIN \
mintplexlabs/anythingllmVisit http://localhost:3001. Create admin account → point at Ollama (http://host.docker.internal:11434) → create a workspace → drag documents in → start chatting.
Frequently asked
Quick answers to common questions
What is AnythingLLM?
AnythingLLM is a rag tool for local AI workloads. All-in-one local RAG application - workspaces, document chat, agents, and embeddable widgets, fully self-hosted.
Is AnythingLLM free and open source?
Yes, AnythingLLM has 63,698 GitHub stars and is licensed under MIT. You can self-host it for free on docker, macos, windows, linux.
What platforms does AnythingLLM support?
AnythingLLM runs on docker, macos, windows, linux.
What hardware do I need for AnythingLLM?
The hardware requirements depend on which models you run. Check our hardware directory for compatible GPUs and systems. AnythingLLM has 63,698 GitHub stars and an active community.
Does AnythingLLM support GPU acceleration?
AnythingLLM supports GPU acceleration via CUDA, Metal, or Vulkan depending on your platform. For the best performance, pair it with an NVIDIA RTX 4090 or 5090.
What are the best alternatives to AnythingLLM?
Popular alternatives include other rag tools in our directory. Browse our full collection at /tool for comparisons, community reviews, and benchmark data to find the right fit for your workflow.
How much does AnythingLLM cost?
AnythingLLM is free-open-source. It is completely free and open source to self-host.
Pairs well with
Complementary tools, models, and hardware
Comments coming soon
Configure NEXT_PUBLIC_GISCUS_REPO_ID and NEXT_PUBLIC_GISCUS_CATEGORY_ID at giscus.app to enable.